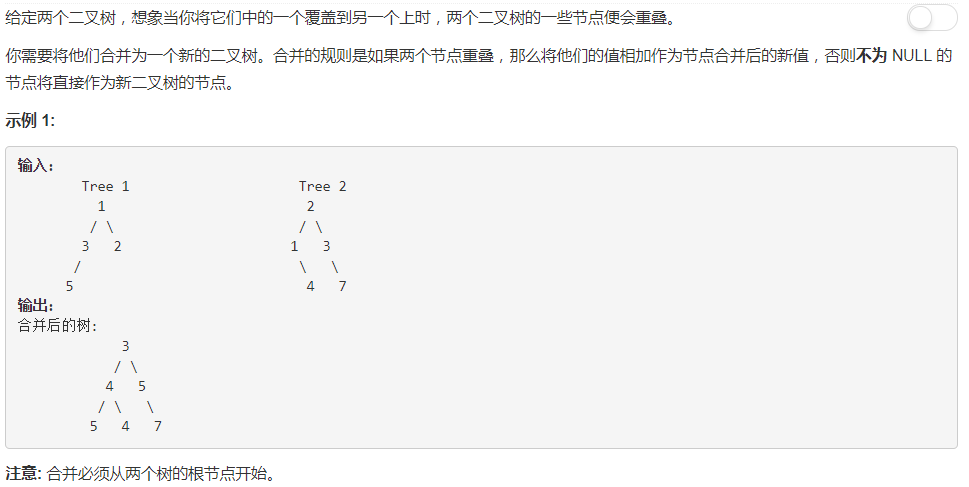
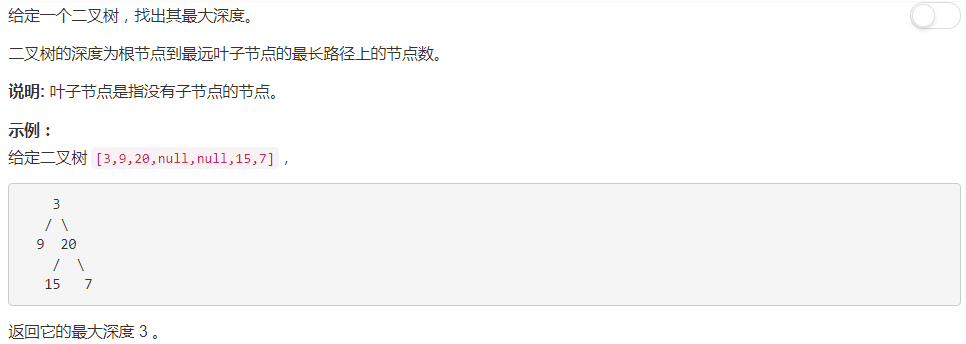
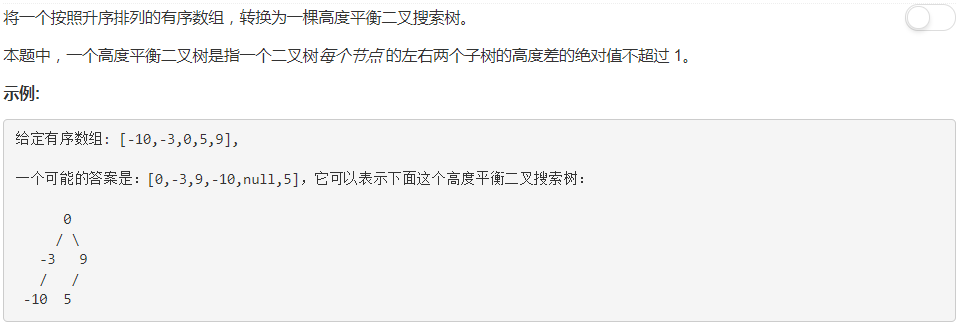
慎用 Python list 乘法
误用 list 乘法
今天刷 LeetCode 碰到一个水题转置矩阵, 这不就是先生成个空的倒置矩阵再填结果嘛,没多想就用 list 乘法上手就写。
class Solution:
def transpose(self, A):
"""
:type A: List[List[int]]
:rtype: List[List[int]]
"""
x, y = len(A), len(A[0])
buff =[[0] * x] * y
for i in range(x):
for j in range(y):
buff[j][i] = A[i][j]
return buff
看似结果非常正确,但是样例输出了一个很奇怪的结果。
我的输入:
[[1,2,3],[4,5,6]]
我的答案:
[[3,6],[3,6],[3,6]]
标准答案:
[[1,4],[2,5],[3,6]]
赶紧在第12行前加上print(buff)一看
我的输入:
[[1,2,3],[4,5,6]]
标准输出:
[[0, 0], [0, 0], [0, 0]]
[[1, 0], [1, 0], [1, 0]]
[[2, 0], [2, 0], [2, 0]]
[[3, 0], [3, 0], [3, 0]]
[[3, 4], [3, 4], [3, 4]]
[[3, 5], [3, 5], [3, 5]]
我的猜测与验证
发现果然列表里的每一个子元素都相等了,猜测可能是 只复制了值的引用,而不是新建了一个对象,接下来就是验证。