GRU 原理
门控循环单元(GRU)与 长短期记忆(LSTM)原理非常相似,同为使用门控机制控制输入、记忆等信息而在当前时间步做出预测。但比起 LSTM,GRU的门控逻辑有些许不同。
GRU 门控逻辑
因为与 LSTM 非常相似,这里就不赘述相同点,仅谈谈他们之间的不同点,想要详细了解,请移步LSTM原理及Keras中实现了解
与 LSTM 的三中门(输入门、遗忘门和输出门)和细胞状态不同,GRU 摆脱了细胞状态仅隐藏状态来传输信息,他只有两个门,一个复位门(reset gate)和一个更新门(update gate)
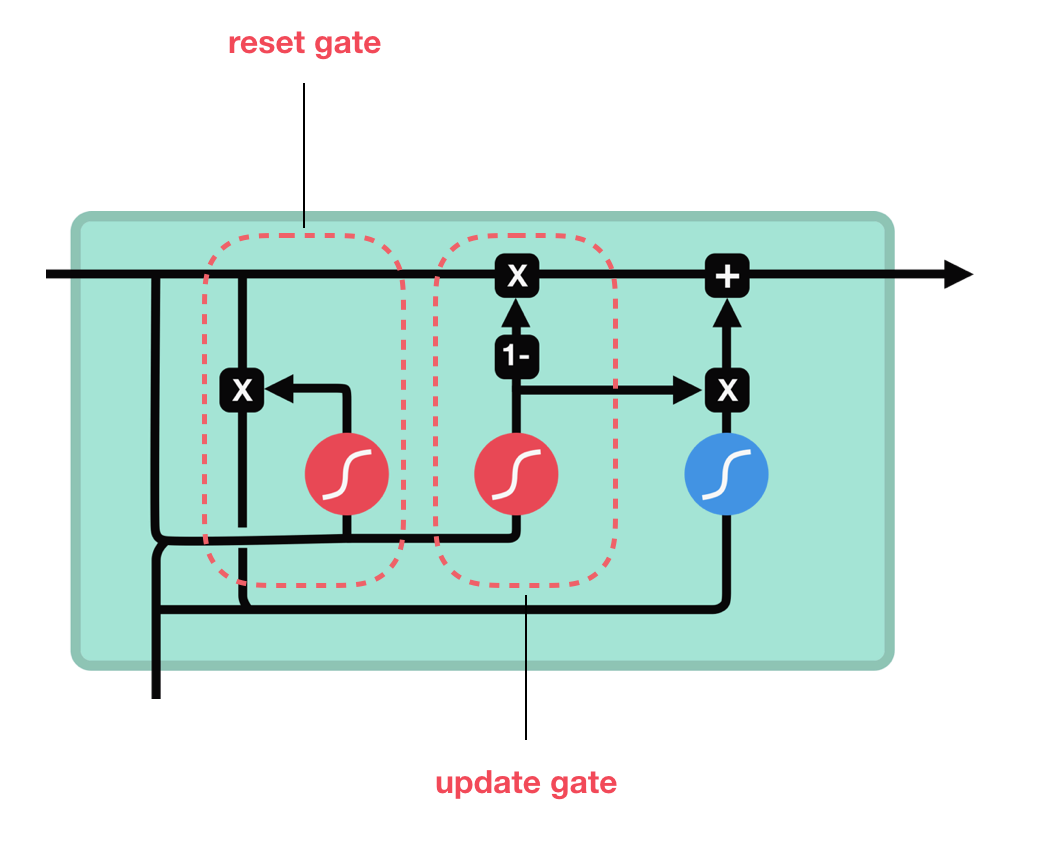
注:GRU 同样也有激活函数tanh(蓝)和Sigmoid(红)
更新门
更新门的作用类似于LSTM的遗忘门和输入门。它决定了要丢弃哪些信息以及要添加的新信息。
重置门
重置门是另一个门,它决定忘记过去的信息量。
GRU优势
因为 GRU 的一个细胞单元门结构少于 LSTM,所以计算量要小于 LSTM,使得他比 LSTM 更快。
GRU 在 Keras 中的实现
代码几乎与同 LSTM 相同,仅需导入 GRU 模型,即可建立与 LSTM 类似的模型结构,参数说明也几乎一致,不再赘述。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent import GRU
model = Sequential()
model.add(GRU(units=100, input_shape=(30, 40), return_sequences=True))
model.add(Dropout(0.2))
model.add(GRU(units=50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=1))
model.add(Activation("linear"))
model.compile(loss="mse", optimizer="adam", metrics=['mae', 'mape'])