本文大致上是基于 caching-in-python 这篇文章的翻译
缓存操作
缓存操作主要有两种类型。缓存如浏览器缓存,服务器缓存,代理缓存,硬件缓存工作原理的读写缓存。当处理缓存时,我们总是有大量的内存需要花费大量的时间来读写数据库、硬盘。 缓存则能帮我们加快这些任务。
读缓存
每次客户端向存储请求数据时,请求都会先去访问与存储相关联的缓存。
- 如果请求的数据在缓存上可用,那么他就是一个Cache hit。
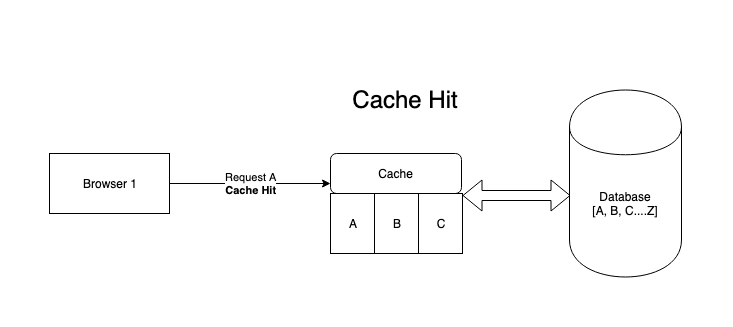
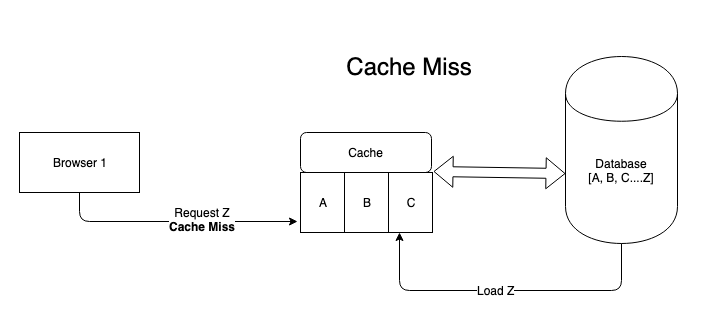
- 如果没有命中缓存。就是Cache miss,则需要去DB中取数据。
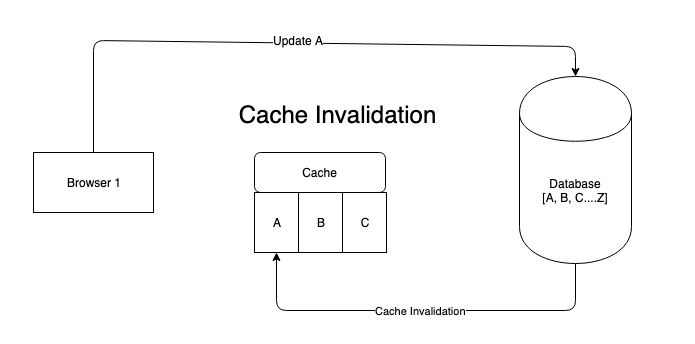
- 当请求缓存的时刻,其他一些进程改变了DB中的数据,从而更新了缓存。导致当前请求的缓存过期,这是一个Cache invalidation,也叫脏数据。
写缓存
顾名思义,写缓存支持快速写操作。设想一个写入量很大的系统,我们都知道向 DB 写入代价很高。而缓存很方便,可以处理 DB 写加载,这些加载稍后会批量更新到 DB。需要注意的是,DB 和缓存之间的数据应该始终保持同步。有3种方法可以实现写缓存。
- Write Through
- Write Back
- Write Around
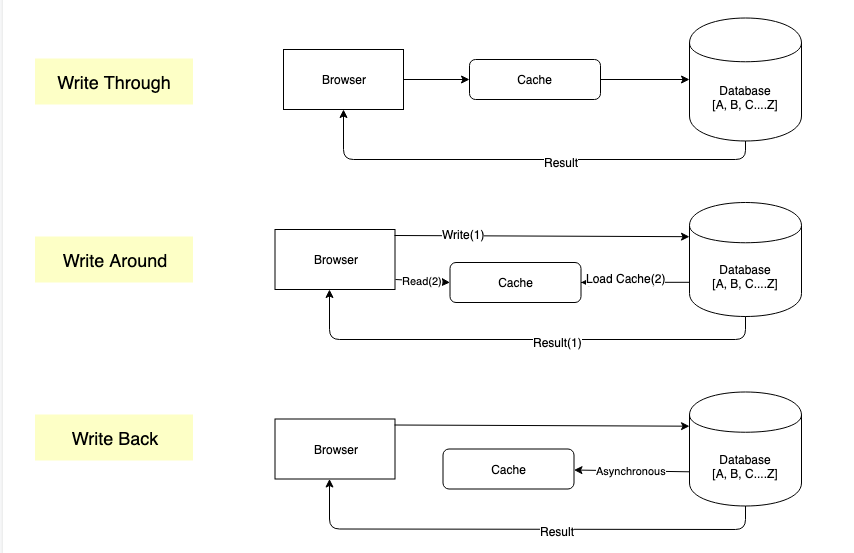
Write Through
客户端先写缓存,缓存再写到 DB ,DB 返回结果给客户端。对缓存要求强一致性可以用这种方式。
- 优点: 缓存和存储之间不会存在数据不匹配,数据一致
- 缺点: 缓存和存储都需要更新,这会产生额外的开销。
Write Back
客户端先写到 DB ,DB 直接返回结果给客户端。之后 DB 定时将数据同步到缓存,下一次客户端读数据时先请求缓存。
- 优点: 加快写缓存的速度
- 缺点: 无法保证数据一致性
Write Around
客户端直接将数据写入 DB,只有在读数据的时候,才从 DB 中加载数据到缓存。
-
优点
- 写入后未立刻读取的数据不会重载缓存
- 减少写方法的延迟
-
缺点
- 读取最近写入的数据将导致缓存丢失,并且不适合这种用例
缓存回收策略
缓存使读写速度更快。那么,只有从缓存中读取和写入所有数据才有意义,而不是使用 DB。但是,只是因为缓存很小所以速度快。缓存越大,搜索时间越长。
所以我们对空间进行优化是很重要的。一旦缓存满了,我们只能通过删除已经在缓存中的数据来为新数据腾出空间。同样,这不能是一个猜谜游戏,我们需要最大化的利用率来优化输出。
以下有几种缓存回收策略:
- LRU - Least Recently Used 最近最少使用
- LFU - Least Frequently Used 最少使用
- MRU - Most Recently Used MRU-最近使用
- FIFO - First In First Out 先进先出
LRU 最近最少使用
顾名思义,当缓存空间不足时,删除最近使用最少的元素。它简单易于实现,听起来很公平,但是对于缓存使用频率来说,比上次访问时有更大的权重,这就引出了下一个算法。
LFU 最少使用
LFU 同时考虑数据的年龄和频率。但是这里的问题是经常使用的数据会长时间滞留在缓存中
MRU 最近使用
究竟为什么有人在讨论了使用频率之后还要使用 MRU 算法呢?我们不是总是重读刚读过的数据吗?不一定。想象图片库应用程序,相册的图片缓存和加载时,你向右滑动。回到上一张照片怎么样?是的,这种情况发生的可能性要小一些。
FIFO 先进先出
当缓存开始像队列一样工作时,您将拥有一个 FIFO 缓存。这非常适合涉及顺序读取和处理数据管道的情况。
LRU的实现
缓存基本上是一个散列表。每个数据进入它是散列和存储使它可以访问在 o(1)。
现在我们如何剔除最近使用次数最少的项目,到目前为止我们只有一个散列函数和它的数据。我们需要以某种方式存储访问顺序。
我们可以使用一个数组,当元素被访问时,我们在这个数组中输入元素。但是在这种方法中元素入栈出栈的时间复杂度将会大大增加。
双向链表可能符合这个目的。每次访问链接列表时添加一个项,并维护它作为哈希表中的引用,使我们访问他的时间复杂度为O(1)。
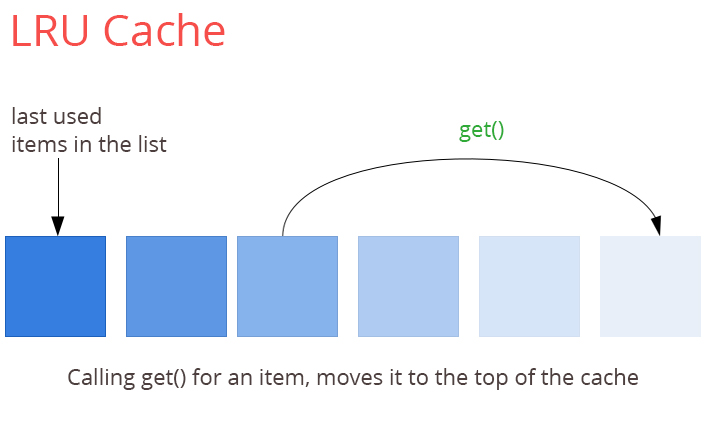
LRU在python中的实现
手动造轮子法
使用一个双端队列实现 LRU 机制,真实的数据存在一个字典当中。
- 队列空,插入元素时。 队列直接左推入元素的键值,并将元素的键值对存进字典。
- 队列空,取元素或元素不存在字典中时。 返回未命中
- 队列满,发生插入时。 压出队列最右端元素键值,并删除字典中的该元素。再将新元素键值左推入队列,并存入字典。
- 队列不空,且元素存在字典,发生读取时。 先将元素的键值移出队列并左推入队列头部,再从字典中取出元素。
from collections import deque
from typing import Any
class LRUCache:
def __init__(self, cache_size: int):
"""
:param cache_size: LRU 队列的大小,超过当前大小时,最近最不常使用的元素将过期
"""
self.cache_size = cache_size
self.queue = deque()
self.hash_map = dict()
def is_queue_full(self):
return len(self.queue) == self.cache_size
def set(self, key: str, value: Any):
if key not in self.hash_map:
if self.is_queue_full():
pop_key = self.queue.pop()
self.hash_map.pop(pop_key)
self.queue.appendleft(key)
self.hash_map[key] = value
else:
self.queue.appendleft(key)
self.hash_map[key] = value
def get(self, key: str):
if key not in self.hash_map:
return -1
else:
self.queue.remove(key)
self.queue.appendleft(key)
return self.hash_map[key]
使用functools中的lru_cache
from flask import jsonify
from functools import lru_cache
@app.route("/user/<uid>")
@lru_cache()
def get_user(uid):
try:
return jsonify(read_user(db, uid))
except KeyError as e:
return jsonify({"Status": "Error", "message": str(e)})
使用 OrderedDict 实现
from collections import OrderedDict
class LRU(OrderedDict):
def __init__(self, max_size=100, *args, **kwarg):
self.max_size = max_size
super(LRU, self).__init__(*args, **kwarg)
def __getitem__(self, key):
value = super().__getitem__(key)
self.move_to_end(key)
return value
def __setitem__(self, key, value):
if key in self:
self.move_to_end(key)
super().__setitem__(key, value)
if len(self) > self.max_size:
oldest = next(iter(self))
del self[oldest]